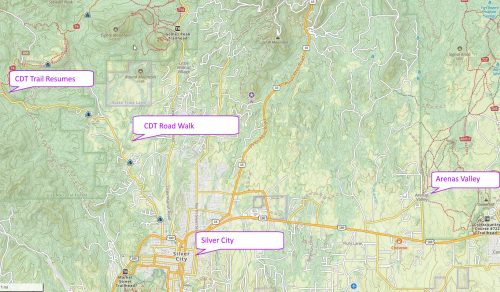
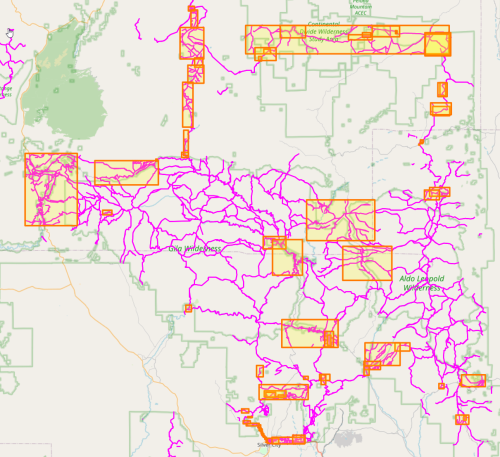
In the previous post we learned how to automagically close short gaps in our trail network, and now we will develop a more refined way of adding longer road-walks without using a long and tedious list of rectangles to define import boundaries as in this post.
Our method involves importing a graph of the Gila that includes both trails and roads, with variable name GTR. With nodes node1 and node2, we find the shortest distance between these nodes in GTR
path = nx.shortest_path(GTR,node1,node2,weight='length')
and then add that path to our original trails graph G. We choose node1 and node2 so that the shortest path between them is very likely to be the road we want to import, and not some alternate path. , and then import this path into our trail graph. The trail graph, G, and the road-and-trail graph GTR share the same node numbers, which is the unique OSMid for that location, which makes this method of selectively importing roads from GTR into G possible.
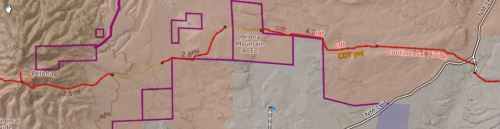
It is fairly easy to look at our map and come up with a list of roads we want to include. (I use the CalTopo website map because its user interface is rather good for finding longitudes and latitudes, and measuring distances.)
road_list = [
( (32.82663, -108.34204), (32.79465, -108.18348), 'silver city cottage san, silver heights, arenas' ),
( (33.01687, -107.94504), (32.93080, -108.01376), 'kelly mesa connector' ),
( (33.02712, -108.13412), (33.04191, -108.22340), 'lake roberts' ),
( (32.91072, -107.70901), (32.92754, -107.75264), 'kingston' ),
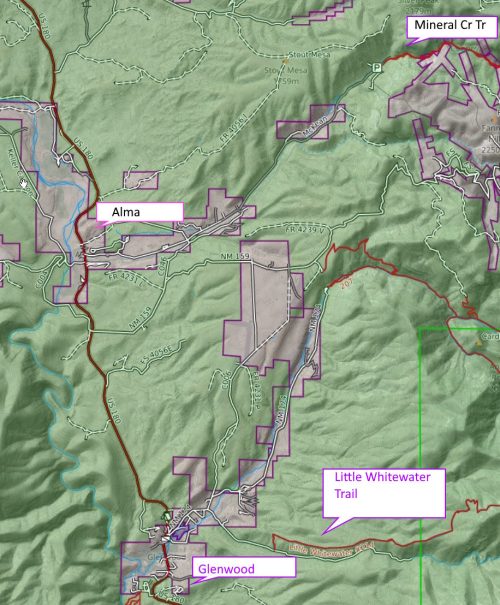
( (33.41948, -108.82821), (33.31934, -108.85576), 'alma/glenwood' ),
( (33.39806, -108.58210), (33.37838, -108.76716), 'bursum road near willow creek campground' ),
( (33.19050, -108.18217), (33.23077, -108.26747), 'gila hot springs' ),
#cdt middle fork alt
( (33.42041, -108.49880), (33.45350, -108.49304), 'snow lake' ),
( (33.49220, -108.48115), (33.74251, -108.47609), 'fr 652, fr94' ),
( (33.74230, -108.47677), (33.74605, -108.48022), 'fr3070' ),
###### cdt wilderness study area
( (33.69325, -108.24452), (33.68589, -108.18571), 'cdt study area near pelona mtn' ),
( (33.67700, -108.05966), (33.68507, -108.02283), 'cdt study area' ),
# aldo
( (33.55441, -107.81135), (33.57859, -107.80749), 'fr 4052P aldo' ),
( (33.51417, -107.83057), (33.52641, -107.80248), 'fr 4052T aldo' ),
( (33.34820, -107.81522), (33.33652, -107.85583), 'near lookout mtn' ),
( (33.33497, -107.82658), (33.34089, -107.84467), 'fr226 aldo' ),
( (33.11088, -107.73054), (33.11153, -107.76046), 'north seco creek' ),
( (33.29079, -108.05481), (33.27013, -108.15834), 'fr225 aldo' ),
]
We also do the mind-the-gap routine from the previous post after adding the longer roadwalks, because these additions fix some of the short gaps for free. We also have refactored our mind-the-gap code to utilize what we learned in this post, so it runs much faster and makes fewer errors in closing gaps.
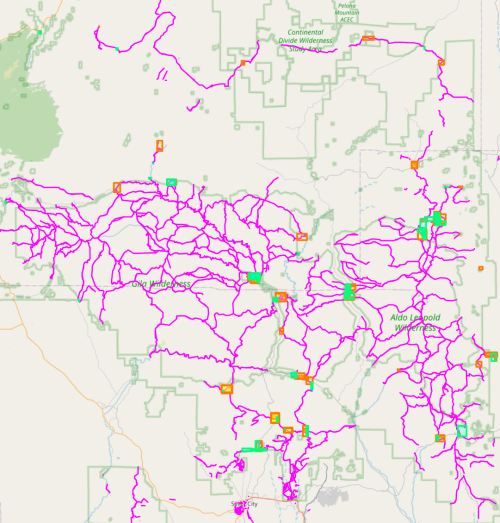
The resulting trail graph is now pleasingly connected.
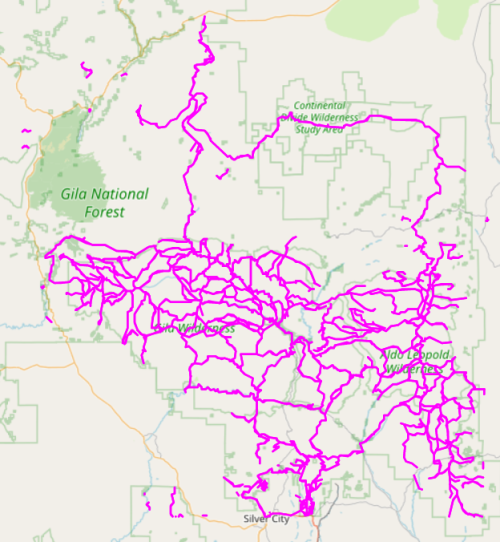
I might make one or two tweaks, but the graph finally looks in good shape. What happens when we run our gradient fuzz search routine now? Actually, the results are not very improved. My current theory is that my trail search algorithm does not correctly handle the case where two 4-nodes are neighbors with each other. With this better-connected graph, there are more 4-nodes, and a higher probability of 4-nodes as neighbors. I will attempt to fix that edge-case next time.
Download source code here.